Sharding
NOTE: Sharding is a new feature with some limitations. Please read them before using it.
OrientDB supports sharding of data at class level by using multiple clusters per class. Under this model each cluster keeps a list of servers where data is replicated. From a logical point of view all the records stored in clusters that are part of the same class, are records of that class.
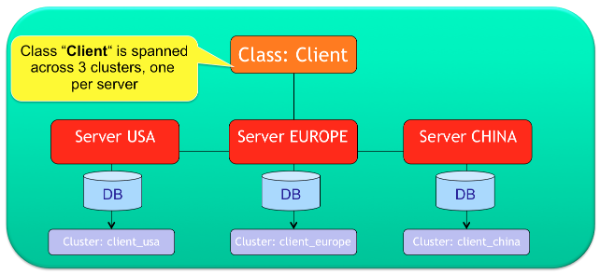
The following is an example that splits the class “Client” in 3 clusters:
Class Client -> Clusters [ client_usa, client_europe, client_china ]
This means that OrientDB will consider any record/document/graph element in any of the three clusters as “Clients” (Client class relies on such clusters). In Distributed-Architecture each cluster can be assigned to one or more server nodes.
Shards, based on clusters, work against indexed and non-indexed class/clusters.
Multiple servers per cluster
You can assign each cluster to one or more servers. If more servers are enlisted then records will be copied across all of the servers. This is similar to what RAID does for Disks. The first server in the list will be the master server for that cluster.
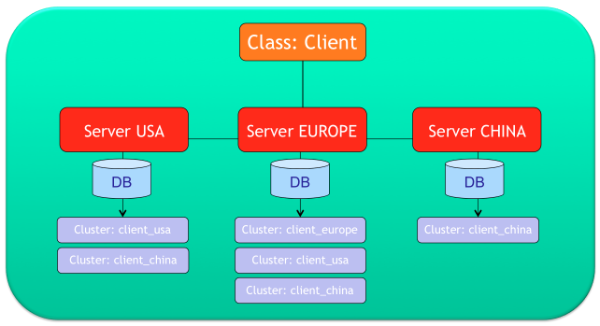
For example, consider a configuration where the Client class has been split in the 3 clusters client_usa, client_europe and client_china. Each cluster might have a different configuration:
client_usa, will be managed by the ”usa“ and “europe” nodesclient_europe, will be managed only by the node, ”europe“client_china, will be managed by all of the nodes (it would be equivalent as writing“<NEW_NODE>”, see cluster “*”, the default one)
Configuration
In order to keep things simple, the entire OrientDB Distributed Configuration is stored on a single JSON file. The distributed database configuration for Multiple servers per cluster JSON object looks somethings like this:
{
"autoDeploy": true,
"readQuorum": 1,
"writeQuorum": "majority",
"executionMode": "undefined",
"readYourWrites": true,
"newNodeStrategy": "dynamic",
"servers": {
"*": "master"
},
"clusters": {
"internal": {
},
"client_usa": {
"servers" : [ "usa", "europe" ]
},
"client_europe": {
"servers" : [ "europe" ]
},
"client_china": {
"servers" : [ "china", "usa", "europe" ]
},
"*": {
"servers" : [ "<NEW_NODE>" ]
}
}
}
Cluster Locality
OrientDB automatically creates a new cluster per each class as soon a new insert operation is performed on a class where the local server has no ownership. When a node goes down, the clusters where the node was master are reassigned to other servers. As soon as that node returns up and running, OrientDB will reassign the ownership of a cluster to the server specified in the owner property if specified, otherwise to the server name indicated as suffix of the cluster (<class>_<node>). For example the cluster customer_usa will be assigned automatically to the server usa if exists in the cluster.
This is defined as “Cluster Locality”. The local node is always selected when a new record is created. This avoids conflicts and allows for the insert of records in parallel on multiple nodes. This also means that in distributed mode you can’t select the cluster selection strategy, because “local” strategy is always injected to all the cluster automatically.
If you want to permanently change the mastership of a cluster, rename the cluster by changing it’s suffix to that of the node you want assign as master.
CRUD Operations
Create new records
In the configuration above, if a new Client record is created on node USA, then the selected cluster will be client_usa, because it’s the local cluster for class Client. Now, client_usa is managed by both USA and EUROPE nodes, so the “create record” operation is sent to both “usa” (locally) and “europe” nodes.
Update and Delete of records
Updating and Deleting of single records always involves all the nodes where the record is stored. No matter the node that receives the update operation. If we update record #13:22 that is stored on cluster 13, namely client_china in the example above, then the update is sent to nodes: “china”, “usa”, “europe”.
Instead, SQL UPDATE and DELETE commands cannot run distributed in case of sharding. For example, the SQL command delete from vertex Client works if the Client class is replicated across all the sevrers, but it won’t work if the class is sharded by throwing a ODistributedOperationException exception with the following reason: “because it is not idempotent and a map-reduce has been requested”.
If you want to execute a distributed update or delete, you can still execute a distributed SQL SELECT against all the shards, and then update or delete every single records in your code. Example to delete all the clients, no matter where they are located:
Iterable<OrientVertex> res = g.command(new OCommandSQL("select from Client")).execute();
for (OrientVertex v : res) {
v.remove();
}
NOTE: if something happens during the iteration of the resultset, you could end up with only a few records deleted.
Read of records
If the local node has the requested record, then the record is read directly from local storage. If it’s not present on the local server, a forward is executed to any of the nodes that have the requested record. This means a network call is made between nodes.
In the case of queries, OrientDB checks for servers where the query targets are located and sends the query to all the involved servers. This operation is equivalent to a Map-Reduce. If the query target is 100% managed on local node, the query is simply executed on local node without paying the cost of network call.
All queries work by aggregating the result sets from all the involved nodes.
Example of executing this query on node “usa”:
SELECT FROM Client
Since local node (USA) already owns client_usa and client_china, 2/3 of data are local. The missing 1/3 of data is in client_europe that is managed only by node “Europe”. “So the query will be executed on local node “usa” and remote node “Europe”. The client will be provided the aggregated result back.”
You can query also a particular cluster:
SELECT FROM CLUSTER:client_china
In this case the local node (USA) is used, because client_china is hosted on local node.
MapReduce
OrientDB supports MapReduce without Hadoop or an external framework like Spark (even if there is a connector), but rather by using the OrientDB SQL. The MapReduce operation is totally transparent to the developer. When a query involves multiple shards (clusters), OrientDB executes the query against all the involved server nodes (Map operation) and then merges the results (Reduce operation). Example:
SELECT MAX(amount), COUNT(*), SUM(amount) FROM Client
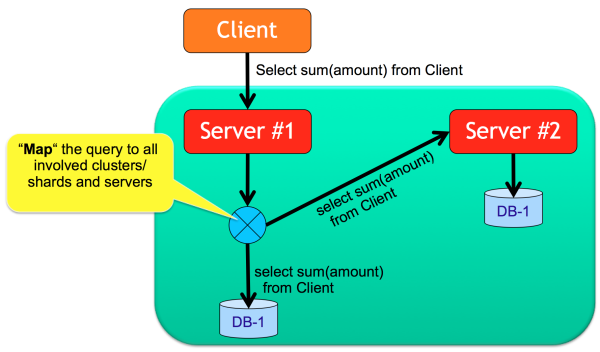
In this case the query is executed across all the 3 nodes and then filtered again on the starting node.

Define the target cluster/shard
The application can decide where to insert a new Client by passing the cluster number or name. Example:
INSERT INTO CLUSTER:client_usa SET @class = 'Client', name = 'Jay'
If the node that executes this command is not the master of cluster client_usa, an exception is thrown.
Java Graph API
OrientVertex v = graph.addVertex("class:Client,cluster:client_usa");
v.setProperty("name", "Jay");
### Java Document API
ODocument doc = new ODocument("Client");
doc.field("name", "Jay");
doc.save( "client_usa" );
Sharding and Split brain network problem
OrientDB guarantees strong consistency if it’s configured to have a writeQuorum to the majority of the nodes. For more information look at Split Brain network problem. In the case of Sharding you could have a situation where you’d need a relative writeQuorum to a certain partition of your data. While writeQuorum setting can be configured at database and cluster level too, it’s not suggested to set a value less than the majority, because in case of re-merge of the two split networks, you’d have both network partitions with updated data and OrientDB doesn’t support (yet) the merging of two non read-only networks. So the suggestion is to always provide a writeQuorum at least at the majority of nodes, even with sharded configuration.
Limitation
- Auto-Sharding is not supported in the common meaning of Distributed Hash Table (DHT). Selecting the right shard (cluster) is up to the application. This will be addressed by next releases
- Sharded Indexes are not supported.
- If
hotAlignment=falseis set, when a node re-joins the cluster (after a failure or simply unreachability) the full copy of database from a node could have no all information about the shards. - Hot change of distributed configuration not available. This will be introduced at release 2.0 via command line and in visual way in the Workbench of the Enterprise Edition (commercial licensed)
- Not complete merging of results for all the projections. Some functions like AVG() doesn’t work on map/reduce
- Backup doesn’t work on distributed nodes yet, so doing a backup of all the nodes to get all the shards is a manual operation in charge to the user
Indexes
All the indexes are managed locally by a server. This means that if a class is spanned across three clusters on three different servers, each server will have it’s own local indexes. By executing a distributed query (Map/Reduce like) each server will use own indexes.
Hot management of distributed configuration
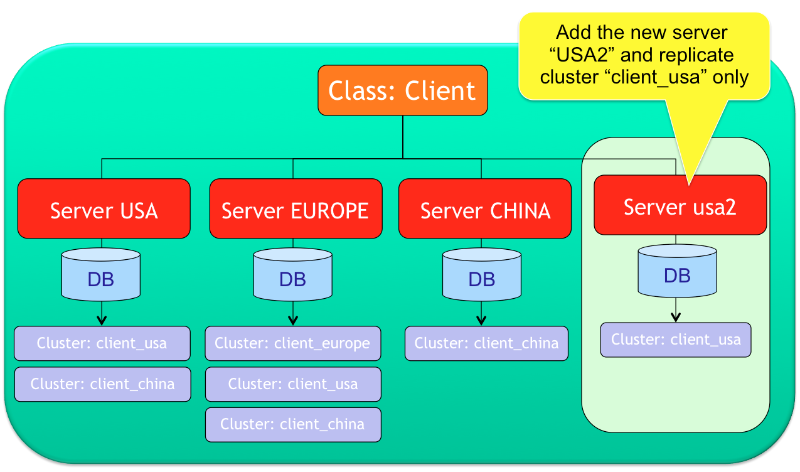
With Community Edition the distributed configuration cannot be changed at run-time but you have to stop and restart all the nodes. Enterprise Edition allows to create and drop new shards without stopping the distributed cluster.
By using Enterprise Edition and the Workbench, you can deploy the database to the new server and define the cluster to assign to it. In this example a new server “usa2” is created where only the cluster client_usa will be copied. After the deployment, cluster client_usa will be replicated against nodes “usa” and “usa2”.